The industry is sitting on the edge of its collective seat as it awaits the release of DeepSeek V4 – which some are expecting next week. DeepSeek, you may remember, was the AI model that debuted a little over a year ago, rocking the AI world and tanking the entire market (not to mention giving NVIDIA the dubious distinction of being the company that lost more market cap in a single day than any other company in history).
What a coincidence, then, that two stories came out this past week painting DeepSeek, and the Chinese government, in a negative and nefarious light (I don’t think the accusations are spurious, but the timing is impeccable). The first story broke on Monday and involved “distillation.” The second appeared the following day, involving GPU access and the shutting out of American chip manufacturers.
Distillation disturbance
On Monday, Anthropic claimed that DeepSeek and two other Chinese AI companies used fake accounts to distill Claude. Distillation, as eWeek describes it, is “a common AI technique where one model learns from another model’s outputs, often to produce a smaller or cheaper system that behaves more like a stronger one.”
The danger, Anthropic asserted, is that models created through illicit distillation are likely to lose the safety guardrails built into American AI systems, such as protections that prevent misuse for bioweapons, cyberattacks, mass surveillance, and more. On top of that, Anthropic argued that distillation also lets Chinese labs bypass U.S. chip export controls by copying U.S. models directly, making their progress look like innovation when it might rely on stolen capabilities.
This leads us to the second DeepSeek-related story of the week, this one involving illicit GPU access and more.
NVIDIA and AMD iced out of early optimization opportunity
The following day Reuters posted an exclusive, “DeepSeek withholds latest AI model from US chipmakers including Nvidia.” DeepSeek, it seems, broke convention by not prioritizing Nvidia and AMD for early software optimization. Instead, Chinese chipmakers — including Huawei — were given a head start. Thanks to advances in AI coding tools and the ability to quickly optimize, however, this early access doesn’t provide the advantage it once did. That being said, it does send a clear message Stateside.
Clusters in Inner Mongolia
On top of this snub, the article quoted US officials as saying that, despite an export ban to China, DeepSeek had been trained on illegally obtained Blackwell chips clustered at a data center in Inner Mongolia. For reference, Blackwell is NVIDIA’s newest and most powerful GPU, whereas the chips previously allowed for export are restricted, scaled-down versions meant to comply with export controls — the NVIDIA H20 and AMD MI308 (slotting between NVIDIA’s H20 and Blackwell chips is H200, whose shipments to China have been stalled over approval guardrails).
Of course, whether China’s access to the latest GPU technology is a good or bad thing with regard to US AI competitiveness depends on who you ask. Anthropic’s CEO Dario Amodei strongly supports tighter export controls and restricting chip sales to China, whereas Nvidia’s CEO Jensen Huang argues that selling advanced chips to China can slow domestic competitors like Huawei by keeping them dependent.
The LLM that came in from the cold
This is intrigue worthy of a John le Carré spy thriller. Both stories point to growing brinkmanship between the two superpowers over AI hegemony. It is characterized by cloak-and-dagger tactics, fears of national security, and opposing views on the same side. This space keeps getting more and more interesting.
TL;DR: The market’s trillion-dollar AI boom is built on one assumption: whoever spends most on infrastructure wins. DeepSeek briefly exposed how fragile that belief is, and how quickly the system could unravel if it’s wrong. It could happen again.
On the last Monday of January, markets lost over a trillion dollars in value. Nvidia alone shed roughly $593 billion, the largest single-day drop in U.S. stock market history.
The cause: DeepSeek R1, an open-source model from China trained for a fraction of the cost of frontier systems. Its release shook market confidence by calling into question the industry maxim that whoever has the most infrastructure wins. (This reevaluation didn’t last long, and by the next day the markets had recovered.)
Nine months later, the market sits at new highs, and infrastructure spending has gone from big to absurd. OpenAI alone has pledged over $1 trillion for computing infrastructure over the next decade—against just $13 billion in annual revenue, a staggering 1:77 ratio.
We’ve entered the age of circonomics: a closed-loop economy where companies are simultaneously customers, suppliers, and investors in each other’s ecosystems. Instead of paying cash, they trade equity, warrants, and GPU access, often leasing back what they’ve sold in increasingly circular agreements. The system resembles a tangled web of interdependence, so tightly coupled that the failure of a few players could destabilize the entire ecosystem.
A single breakthrough, whether in architecture, algorithmic efficiency, or data movement, could render these trillion-dollar bets obsolete overnight. DeepSeek already proved that “bigger is better” isn’t a law of nature. A new open-source model that’s merely “good enough” could shift value upward, from infrastructure to applications, undermining the capital structure beneath today’s AI giants.
This in turn could ripple through markets, exposing how much of today’s prosperity depends on the myth of infinite scale.
AI is unquestionably a once-in-a-generation technological shift. The question is whether it truly requires mythic levels of capital expenditure to get there. When the correction eventually comes, AI won’t die; it will evolve. The next phase will reward efficiency over magnitude: smaller, modular models, decentralized compute, open source and open architectures.
In short, disruption won’t end AI, it will force it to grow up.
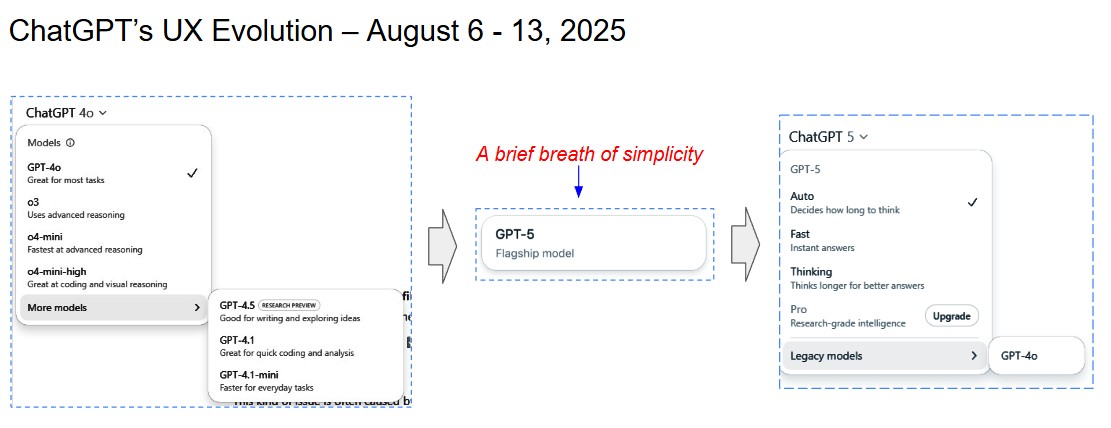
About a month ago I wrote about my frustration with ChatGPT-4o’s pull-down menu and its mess of mismatched models. I ended my post saying that I hoped ChatGPT 5 would address this. Last Thursday my prayers were answered. The pull-down was gone and with it the hodgepodge of models. In its place there was one simple clean button.
The backlash
Not long after the new model and its clean UX debuted, a hue and cry erupted in the web-o-sphere. The biggest complaint was the disappearance of GPT-4o. People were both angry and frustrated at the loss of friendliness and companionship that 4o brought (not to mention the fact that it had been incorporated into many workflows). To OpenAI’s credit they listened and responded. Within days 4o was back on the home screen as a “legacy model.”
Fun fact!
When I first started writing this, I wasn’t sure which keys to hit when typing “4o.” The “0” looked a couple of points smaller than the “4,” but I couldn’t quite tell. After asking the source, I learned it wasn’t a zero at all—it was a lowercase “o.” It turns out the “o” stood for omni, signaling multimodal capability. (I’ve got to believe that I’m not the only one surprised and confused by this)
As a follow up I asked if GPT-5 is multimodal. The answer: “Indeed.” Which then raises another question—why isn’t it called “GPT-5o”? But I digress.
The return of the pull-down
Along with 4o, came the reintroduction of the pull-down menu which, in addition to the “Legacy Models” button, presented four thinking modes to choose from (it seems the thinking modes were added in response to what some users felt was GPT-5’s slow speed and lack of flexibility).
Auto – decides how long to think
Fast – instant answers
Thinking – thinks longer for better answers
Pro – Research-grade intelligence (upgrade)
While power users must have rejoiced, I found myself, once again, confronted with a set of options lacking helpful explanations. While it was certainly an improvement over GPT-4o’s mess of models and naming conventions I found myself left with many questions:
While power users must have rejoiced, I found myself, once again, confronted with a set of options lacking helpful explanations. While it was certainly an improvement over GPT-4o’s mess of models and naming conventions I found myself left with many questions: What criteria does Auto use to determine how long to think? What tradeoffs come with Fast? What exactly qualifies as “better” in Thinking? if I’m impatient will I get lesser answers? And what the heck is “research-grade” and why would I pay more for it?
Just like GPT-4o where I rarely ventured beyond the main model, so far I have kept GPT-5 in auto mode.
Grading the model
Before grading the models myself I decided to get ChatGPT 5’s thoughts. I asked the AI to focus its grading on the UX experience, specifically to what extent a user would be able to quickly and confidently pick the right mode for a given task.
Surprisingly, it graded itself and its predecessor just as I would have. GPT-5 gave the GPT-4o UX a C– and its own, a B-. From there it went through and critiqued the experiences in detail.
At the very end, GPT-5 offered to put together a proposal for a “redesigned hybrid menu that takes GPT-5’s simplicity and pairs it with short, task-oriented descriptions so users can choose confidently without guesswork.” If only OpenAI had access to a tool like this!
Your mileage may vary
Over the past week I’ve used GPT-5 a fair amount. While I can’t measure results objectively, Auto seems to choose well. Writing, research, and analysis have been solid.
Compared to 4o I found that it spent significantly more time researching and answering questions. Not only have I noticed the increase in thinking time, but for the first time I witnessed “stepwise reasoning with visible sub-tasks.” Component topics were flashed on the screen as GPT-5 focused on each one at a time. The rigor was impressive, and the answers were detailed and informative.
Was it an improvement over 4o? Hard to tell—but the process felt more deliberate and transparent, even if it took longer.
Back to UX
And yet, we’re back to a cluttered pull-down. OpenAI isn’t alone—Anthropic and Gemini also present users with a maze of choices that lack clarity. What’s surprising is how little attention is paid to basic UX. Even simple fixes—like linking to a quick FAQ or watching a handful of users struggle through the interface—would go a long way.
As LLMs become interchangeable, the real competition will move higher up the stack. At that point, user experience will outweigh minor gains in benchmarks. It makes sense to start practicing now.
At their foundation, AI systems are massive data engines. Training, deploying, and operating AI models requires handling enormous datasets—and the speed at which data moves between storage and compute can make or break performance. In many organizations, this data movement becomes the biggest constraint. Even with better algorithms, companies frequently point to limitations in data infrastructure as the top barrier to AI success.
During the recent AI Infrastructure Field Day, Solidigm—a maker of high-performance SSDs built for AI workloads—shared how data travels through an AI training workflow and why storage plays an equally important role as compute. Their central point: AI training succeeds when storage and memory work in sync, keeping GPUs fully fed with data. Since high-bandwidth memory (HBM) can’t store entire datasets, orchestrating the flow between storage and memory is essential.
The takeaway: Well-designed storage architecture ensures GPUs can run at peak capacity, provided data arrives quickly and efficiently.
Raw Data → Data Preparation
Raw Data Set The process begins with large volumes of unstructured data written to disk, usually on network-attached storage (NAS) systems optimized for density and energy efficiency.
Data Prep 1 Batches of raw data are pulled into compute server memory, where the CPU performs ETL (Extract, Transform, Load) to clean and normalize the information.
Data Prep 2 The cleaned dataset is then stored back on disk and also streamed to the machine learning algorithm running on GPUs.
Training → Archiving
Training From a data perspective, training generates two outputs:
The completed model, written first to memory and then saved to disk.
Multiple “checkpoints” saved during training to enable recovery from failures—these are often written directly to disk.
Archive Once training is complete, key datasets and outputs are archived in network storage for long-term retention, audits, or reuse.
NVIDIA GPUDirect Storage
A noteworthy technology in this process is NVIDIA GPUDirect Storage, which establishes a direct transfer path from SSDs to GPU memory. This bypasses the CPU and system memory, reducing latency and improving throughput.
Final Thought
While having more data can lead to better model accuracy, efficiently managing that data is just as important. Storage architecture decisions directly impact both performance and power usage—making them a critical part of any serious AI strategy.
My son and I were watching a Malcolm in the Middle marathon recently when, rather than typical detergent or Nissan ads, multiple 30-second spots from Meta popped up. Each advert highlighted the virtues of open source through their Llama LLM and ended with taglines like, “Open source AI. Available to all, not just the few.” The message I took away was: Open Source AI benefits everyone. Llama is Open Source. Llama benefits everyone.
These weren’t your usual niche tech ads (see two examples below)—they were slick, mainstream productions airing during a popular family sitcom. Surprised and puzzled, I did some digging and learned these ads were rolled out at the end of last year and intensified around April and May to coincide with the release of Llama 4 and leveraging the momentum from Llama 3.1.
But is Llama truly open source? No. The Open Source Initiative (OSI), the definitive authority on open source standards, notes several critical shortfalls:
Commercial Restrictions: Limit on large-scale commercial use excludes key competitors.
Redistribution Restrictions: Violates principles of unrestricted redistribution.
Training Data Not Public: OSI’s AI-specific definition requires open access to training datasets.
Regional Restrictions: Certain geographic uses (e.g., in the EU) may be prohibited.
Meta can set whatever restrictions they want on their software, but if they impose the above restrictions, Llama doesnt qualify as “open source.”
Do the ends justify the means? On one hand, Labeling Llama as open source could dilute the definition, opening it up to interpretation and potentially undermining genuine open-source projects. Critics argue this erodes trust, blurs established norms, and disadvantages truly open projects.
On the other hand, there’s a notable benefit: Meta’s mainstream campaign significantly boosts public awareness and portrays open source as beneficial, democratizing technology and driving innovation.
Ultimately, the challenge is balancing the immense public exposure Meta’s Llama TV ads provide to the open source movement against concerns about accurately preserving the open source definition. The key question for the open source community is not whether these TV ads cause harm—they likely don’t—but how to maintain the integrity of what “open source” really means, which in the new world of AI, has become even harder.
Two examples
Meta AI TV Spot, ‘Open Source AI: Everyone Benefits’ (prosthesis) “Open source AI is an open invitation. To take our model and build amazing things… When AI is open source, it’s available to all, and everyone benefits.
Meta AI TV Spot, ‘Open Source AI: Collaboration’ (start up) “Open source AI allows universities, researchers, and scientists to collaborate using Meta’s free open-source AI Llama… potentially fast-tracking life-saving medications.”
One of the companies that impressed me at AI Infrastructure Field Days was Solidigm. Solidigm, which was spun out of Intel’s storage and memory group, is a manufacturer of high-performance solid-state drives (SSDs) optimized for AI and data-intensive workloads. What I particularly appreciated about Solidigm’s presentation was, rather than diving directly into speeds and feeds, they started by providing us with a broader context. They spent the first part of the presentation orientating us and explaining the role storage plays and what to consider when building out an AI environment. They started by walking us through the AI data pipeline: (for the TL;DR see “My Takeaways” at the bottom)
Breaking down the AI Data Pipeline
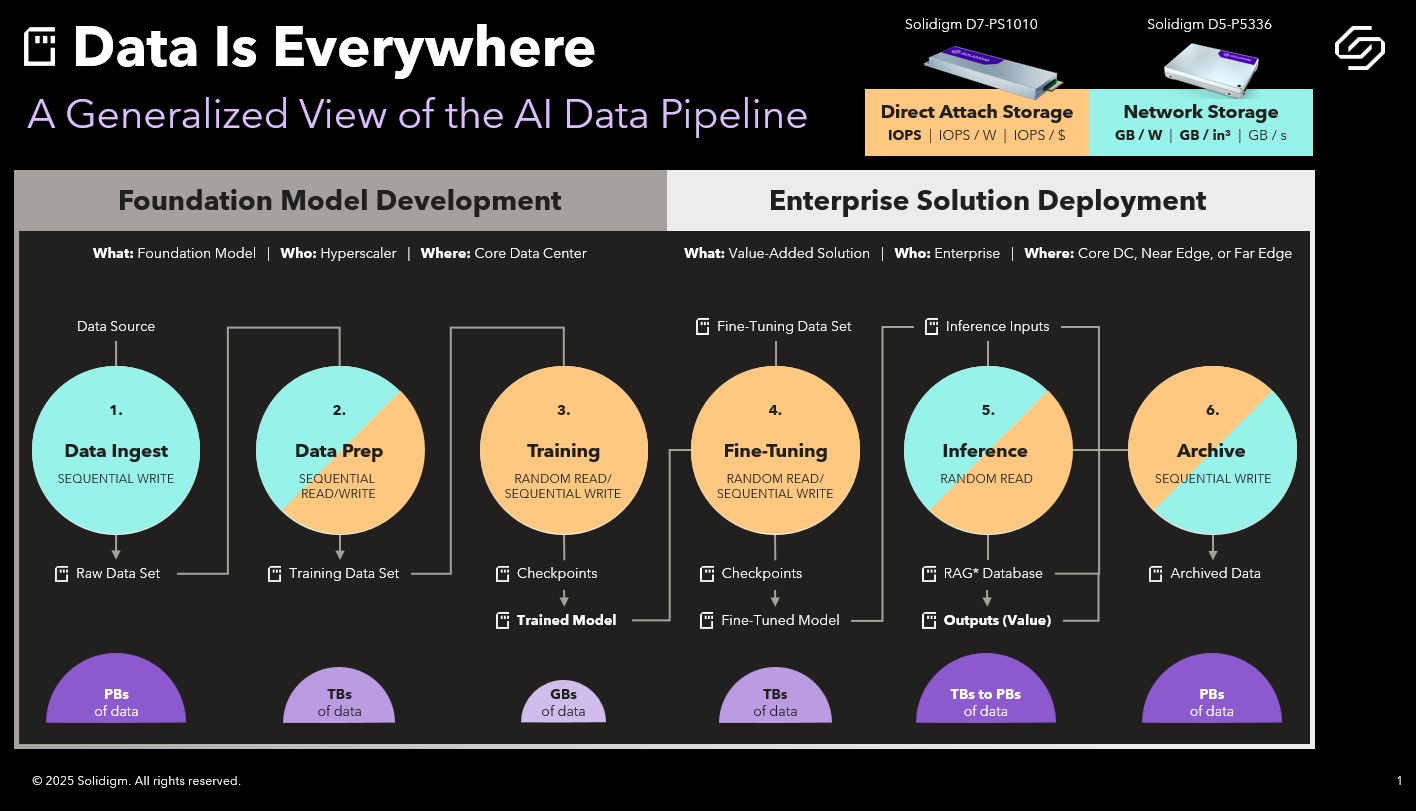
Solidigm’s Ace Stryker kicked off their presentation by breaking the AI data pipeline into two phases: Foundation Model Development on the front end and Enterprise Solution Deployment on the back end. Each of these phases is then made up of three discrete stages.
Phase I: Foundation Model Development.
The development of foundation models is usually done by a hyper-scaler working in a huge data center. Ace defined foundation models as typically being LLMs, Recommendation Engines, Chatbots, Natural Language Processing, Classifiers and Computer Vision. Within foundation model development phase, raw data is ingested, prepped and then used to train the model. The discreet steps are:
1. Data Ingest: Raw, unstructured data is written to disk.
2. Data Preparation: Data is cleaned and vectorized to prepare it for training.
3. Training: Structured data is fed into ML algorithms to produce a base (foundation) model.
Phase II: Enterprise Solution Deployment
As the name implies, phase II takes place inside the enterprise whether that’s in the core data center, the near edge or the far edge. In phase II models are fitted and deployed with the goal of solving a specific business problem:
4. Fine-Tuning: Foundation models are customized using domain-specific data (e.g., chatbot conversations).
5. Inference: The model is deployed for real-time use, sometimes enhanced with external data (via Retrieval Augmented Generation).
6. Archive: All intermediate and final data is stored for auditing or reuse.
Data Flows and Magnitude
From there took us through the above slide which lays out how data is generated and flows through the pipeline. Every item above with disk icon represents the substantial data that is generated during the workflow. The purple half circles give a sense of the relative size of the data sets by stage. (an aside: it doesn’t surprise me that Inference is the stage that generates the most data but I wouldn’t have thought that Training would be significantly less than the rest).
Data Locality and I/O Types
Ace ended our walk through by pointing out where all this data is stored as well as what kinds of disk activity takes place at each stage.
Data Locality:
Above, Network Attached Storage is indicated in blue and Direct Attached Storage is called out in yellow ie Ingest is pure NAS, Training and Tuning are all DAS, Prep, Inference and Archive are 50/50. Basically, early and late stages rely on network-attached storage (NAS) for capacity and power efficiency. Middle stages, on the other hand, use direct-attached storage (DAS) for speed, ensuring GPUs are continuously fed data. The takeaway: direct attached storage for high-performance workloads and network storage for larger, more complex datasets.
I/O Types:
As Ace explained, it’s useful to know what kinds of disk activity are most prevalent during each stage. And that knowing the I/O characteristics can help ensure the best decisions are being made for the storage subsystem. For example,
Early stages favor sequential writes.
Training workloads are random read intensive.
Something else the presentation stressed was the significance of GPU direct storage, which can reduce CPU utilization and improve overall AI system performance by allowing direct data transfer between storage and GPU memory.
My takeaways
It may sound corny but Data is the lifeblood of the AI pipeline
The AI data pipeline has both a front end and a back end. The back end usually sits in a hyperscaler where, after being ingested and prepped, the data is used to train the model. The front end is within the enterprise where the model is tuned for business-specific use then used for inference with the resulting data archived for audits or reuse.
Not only is there a lot of data in the pipeline but it grows (data begets data). Some stages amass more data than others.
There isn’t one storage type that dominates. In those stages like Data Ingest where density and power efficiency are key you want to go with NAS whereas in areas like Training and Fine Tuning, where you want performance to keep the GPUs busy, DAS is what you want.
At Cloud Field Day, I sat in on a presentation from Catchpoint, a company focused on digital experience monitoring. Their platform delivers real-time insights into the performance and availability of applications, services, and networks. What sets Catchpoint apart is how they’re reframing observability—moving away from infrastructure-centric monitoring and placing the focus squarely on end-user experience.
It started with a three-hour outage
Catchpoint’s origin story starts with co-founder and CEO Mehdi Daoudi, who previously led a team at DoubleClick (later acquired by Google) responsible for delivering 40 billion ad impressions per day. After accidentally triggering a three-hour outage, he became deeply committed to performance monitoring. “If I had to run the same team I ran back then, I would focus on the end user first,” he said. “Because that’s what matters.”
Users Don’t Live in your Data Center
“Traditional monitoring starts from the infrastructure up,” explained Mehdi explained: “but users don’t live in your data center.” Catchpoint flips the model by simulating real user activity from the edge, surfacing issues like latency, outages, or degraded performance before they affect customers—or make headlines.
no CIO wakes up hoping for “50% availability.
Mehdi illustrated the point with a story: walking into a customer network operations center where every internal system showed green lights—yet no ads were being delivered. The problem? Monitoring was focused inside the data center, not from the perspective of users on the outside. That gap in visibility led to costly blind spots.
In today’s distributed, cloud-first world—where user experience depends on a web of DNS providers, CDNs, edge nodes, and cloud services—that lesson is even more relevant. The internet may be a black box, but users expect it to work seamlessly, and they’ll publicly let you know when it doesn’t.
Catching the unknown unknowns
By reducing both mean-time-to-detect (MTTD) and mean-time-to-repair (MTTR), Catchpoint helps teams catch “unknown unknowns”—the unexpected failures APM tools often miss until it’s too late. It’s not just about knowing what went wrong, but knowing before your customers notice.
In a fragile, high-stakes digital environment, monitoring isn’t just an IT concern anymore—it’s a business-critical capability. As Mehdi put it, no CIO wakes up hoping for “50% availability.” Reliability is not a nice-to-have.
At Cloud Field Day 22, cybersecurity leader Fortinet shared its vision for managing the growing complexity of cloud-native environments. Their focus: enabling security teams to move faster, reduce alert fatigue, and make smarter decisions using AI-driven threat detection and automation.
Navigating Modern Cloud Security Challenges
In traditional data centers, firewalls protected predictable network chokepoints. But in the cloud, the security landscape is fluid—defined by ephemeral workloads, dynamic ingress/egress, and fragmented microservices. These cloud-native architectures make visibility and threat correlation far more difficult.
Fortinet’s response is to empower security operators with a cloud-native security platform designed to turn noisy telemetry into meaningful, actionable insight.
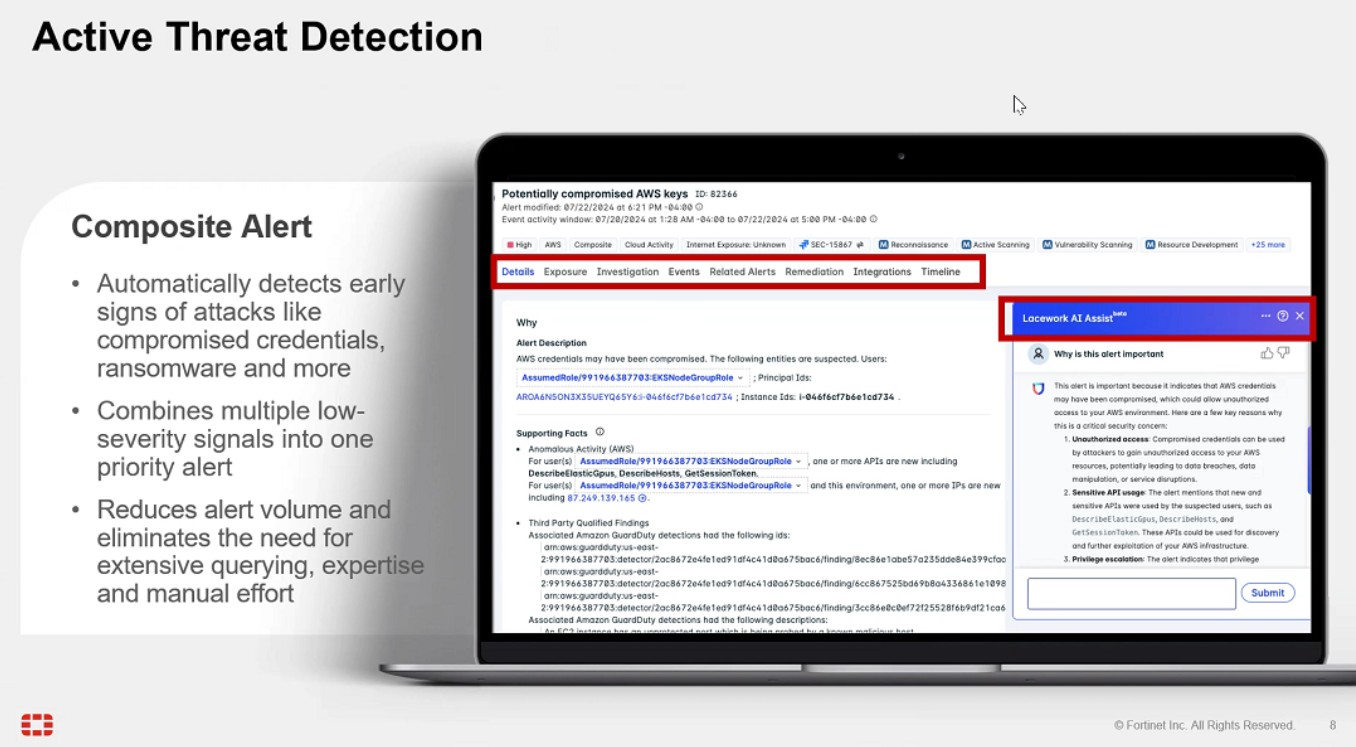
Inside Fortinet’s CNAPP: Composite Threat Detection at Scale
Fortinet’s Cloud-Native Application Protection Platform (CNAPP) is a unified, vendor-agnostic solution that protects across the entire cloud application lifecycle—from source code and CI/CD pipelines to infrastructure and production workloads.
Rather than simply aggregating security data, CNAPP uses machine learning to correlate low-level signals into composite risk insights—multi-source, high-confidence threat narratives. This AI-powered threat detection helps teams separate real attacks from benign anomalies and respond faster, with fewer false positives.
Built for Security Operators: AI + Context
A standout feature is the integration of large language model (LLM) assistants into the analyst workflow. These LLMs provide pre-investigation context, explain attack chains, and suggest tailored remediation actions. It’s like having a virtual teammate triaging alerts in real-time.
CNAPP also supports:
Software Composition Analysis (SCA) for code-level vulnerabilities
Infrastructure monitoring for cloud misconfigurations
Pipeline inspection for DevSecOps visibility
Runtime protection across containers, VMs, and serverless apps
Whether identifying CVEs in Kubernetes clusters or flagging anomalies in your VPC, Fortinet delivers a holistic view of cloud risk.
Final Thoughts
As organizations scale across multi-cloud and hybrid environments, cloud-native threat detection and security automation become critical. Fortinet’s CNAPP shows what’s possible when AI meets cloud security—turning volumes of raw data into clarity, action, and real-time resilience.
Earlier this year, I had the opportunity to participate as a delegate at Cloud Field Day in Santa Clara. As delegates, we engaged directly with the presenting companies, offering feedback on what resonated, what needed clarification, and how their strategies could evolve.
The first presenter was Infoblox, a company that merges networking and security into a unified solution, more specifically they are focused on DDI — that’s DNS, DHCP, and IPAM. Other than an acronym of acronyms, what exactly is DDI? I soon found out as Chief Product Officer Mukesh Gupta explained how this combination of “boring” network services is critical in today’s messy, manual, and fragmented hybrid multi-cloud environments.
What Really Is DDI and Why Does It Matter?
DDI is about managing the “naming,” “numbering,” and “locating” of everything connected to a network — whether it’s a laptop, server, phone, or cloud service. Specifically it is made up of three foundational network services:
DNS (Domain Name System): Translates human-readable domain names (like google.com) into IP addresses.
DHCP (Dynamic Host Configuration Protocol): Automatically assigns IP addresses to devices on a network.
IPAM (IP Address Management): Manages the allocation, tracking, and planning of IP addresses across an organization.
These services form the invisible infrastructure behind every enterprise network. Mukesh described DDI as the “electricity” of networking — when it goes down, everything stops.
Multi-Cloud Challenges and DDI
Mukesh outlined three key trends currently reshaping enterprise infrastructure:
Hybrid multi-cloud adoption Most organizations now operate across a mix of public cloud providers and on-premises infrastructure.
SaaS-first, cloud-first strategies Enterprises are rapidly moving off legacy systems (especially post-VMware acquisition) in favor of cloud-native approaches.
Increasing cybersecurity threats Attackers are more frequent, more sophisticated, and more damaging than ever before.
These trends introduce real complexity for DDI. Key challenges include:
Fragmented DNS systems across multiple clouds
Inconsistent APIs that make automation difficult and expensive
IP address conflicts due to disconnected systems
Stale DNS records that introduce security vulnerabilities
Real-world example: A major New York bank allowed cloud teams to use native DNS tools. One day, a simple typo in a DNS entry brought down the entire bank for four hours, costing them millions.
Infoblox’s Answer: An Integrated Platform
To address these pain points, Infoblox introduced the Infoblox Universal DDI™ Product Suite. This integrated platforms provides a centralized, automated, and cloud-managed way to run critical network services (DNS, DHCP, IPAM) across complex hybrid and multi-cloud environments.
Key Features:
Unified management layer Manage DNS across on-prem, branch, and cloud from a single interface.
Universal IPAM & asset visibility Real-time insights into IP usage and resource status.
Conflict detection & stale record resolution Automatically identify and resolve subnet overlaps and outdated DNS entries.
Built-in security Use DNS as a security control point to detect and block threats.
The platform supports physical, virtual, and cloud-based DNS servers, and integrates with automation tools like Terraform and Ansible. It also maintains backward compatibility via API replication, ensuring existing workflows stay intact.
Security Through DNS
One of the most compelling elements of Infoblox’s platform is how it uses DNS as a security layer.
Since nearly every internet communication starts with a DNS query, Infoblox can analyze DNS traffic patterns to:
Detect ransomware activity
Prevent data exfiltration
Block malicious domains in real time
By combining DNS logs with threat intelligence feeds, Infoblox transforms a foundational service into a proactive security shield.
The Future is Unified DDI
As enterprises deepen their multi-cloud investments, unified management and visibility across distributed infrastructure becomes invaluable. Infoblox’s Universal DDI™ Product Suite delivers this allowing organizations to manage DNS, DHCP, and IP address assignments consistently across data centers, cloud providers, and edge environments — all from a single interface.
While DNS, DHCP, and IPAM may seem behind-the-scenes, they are essential to:
Prevent outages
Accelerate cloud operations
Strengthen enterprise security
In a world where spreadsheets and siloed tools can bring down billion-dollar operations, Infoblox’s Universal DDI is something definitely worth checking out.
10 years ago, Dell’s first developer system, the Ubuntu-based XPS 13 developer edition became available in the US and Canada. What made this product unique was not only that it had been developed out-of-process and by a team largely made up of volunteers, but it targeted a constituency completely new to Dell. On top of that, nine months prior to launch the offering was nothing more than a recommendation supported by a handful of slides.
Today’s 12th generation Dell XPS Plus developer edition
Fast forward a decade and that initial developer edition is in now its 12th generation and has grown into an entire portfolio of developer systems. In addition to the XPS 13 developer edition, this portfolio now includes the Linux-based Precision mobile and fixed workstations, targeted not only at developers but data scientists as well.
You may be wondering not only how this volunteer-driven effort, targeted at what was seen as a niche audience, has survived, and thrived over the last 10 years. To learn this and what’s next for Dell and developers, read on….
Whey are all the best ideas impractical?
Our story begins back in the second half of 2011 with an impractical idea. At that time, myself and a couple of others had been tasked with finding ways Dell could serve web companies beyond infrastructure. To help us think through opportunities, we brought in Stephen O’Grady of the analyst firm, Redmonk to discuss potential approaches and solutions. An idea Stephen brought up was to deliver a Linux-based laptop that “just worked” and was targeted at application developers While Dell had been offering laptops preloaded with Linux for years, those offerings had been lower-end systems positioned as value solutions. If the idea was to target application developers, the offering would need to be based on a top-of-the-line system.
We loved the idea! Unfortunately, we knew that our client group would never go for it. The customer segments that Dell traditionally supported required huge volumes and a developer laptop would be seen as serving a “niche” market. We filed the idea away under, “great but impractical.”
Hark, an innovation fund
A few months later however, providence shown in the form of a recently established innovation fund.We realized that if we were ever to get support for our idea, this fund would be our best shot.
In order to put together a realistic proposal we started by enlisting a couple of interested engineers to provide a technical perspective. Next, we reached out to Canonical, the commercial sponsor behind Ubuntu, to gauge their interest (they were all in). With the help of Canonical, our little team performed some back of the envelope calculations to determine the resources needed to deliver a developer laptop. Based on our quick analysis we decided that it looked do-able and that we would worry about the details later.
The pitch
The deck I ended up delivering to the innovation team was far from a typical Dell presentation. The deck contained no numbers, no cost estimates and no revenue projections. Instead, I described the influence that developers had in the IT buying process and explained that the goal of the program was not to make money* but to raise Dell’s visibility with an influential community. By delivering a high-end Linux-based developer system, not only would we have something that no other major OEM offered, but more importantly it would help us to build trust within this community. This in turn would not only benefit our client business but the broader Dell as well.
I finished my presentation and rather than a standing ovation the innovation team thanked me for my time and told me they’d get back to us.
*Note: the program has not only paid for itself but has delivered tens of millions of dollars in revenue
Don’t look stupid
A month later, on the Ides of March, we were contacted and told that we were being given 6 months and a little pot of money to prove the value and viability of a developer laptop. We immediately formed an “official” core team and circled back with Canonical. Together we dug in and began determining what was needed to ensure that, directly out of the box, Ubuntu would run flawlessly on the XPS 13.
At the same time, we needed to make doubly sure that if we went public the community wouldn’t see Dell as tone deaf and “not getting it.” To help us determine this, we enlisted three local application developers, aka “alpha cosmonauts,” to act as sanity checkers and to provide early guidance. In parallel I headed to the west coast and met with both Google and Amazon and told them what we were proposing. While neither company placed an order for 10,000 units, I wasn’t laughed out of the room. Seeing this as a positive sign and with the support of our alpha cosmonauts, our team had the confidence to move forward.
Drivers, patches and contributing code
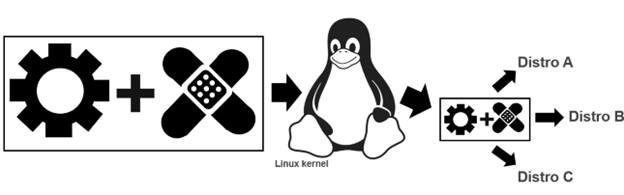
To ensure that Ubuntu works flawlessly on a Dell system, Dell, Canonical and device manufacturers need to work together. The process starts when the device manufacturers write open source drivers, allowing their devices (eg wireless cards, trackpads etc) to work on a specific Dell laptop or workstation. Next, to go from “works pretty well” to “just works“ these drivers need to be tweaked.
Tux attribution: gg3po, Iwan Gabovitch, GPL , via Wikimedia Commons
This tweaking comes in the form of open source patches which are jointly created by Dell and Canonical. These patches are then added to the original driver code and all of which is contributed upstream to the mainline Linux kernel.
While these drivers and corresponding patches are initially created to be used with Ubuntu, because code from the mainline kernel makes its way back downstream, all distros eg Fedora, OpenSuSE, Arch, Debian etc. can use it. This sharing of the code gives the community the ability to run the distro of their choice beyond Ubuntu.
After a couple of frantic months of coding and patching together internal support, the team was ready to get public feedback. To reflect the project’s exploratory nature, rather than issuing a press release or posting an announcement on Dell’s corporate blog, we decided to post the announcement on my blog.
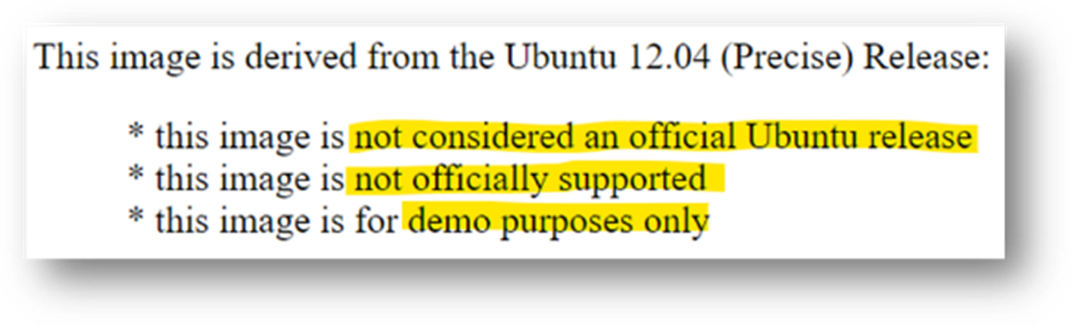
So that developers knew what they were getting into the OS image was clearly marked
We explained that the image was based on Ubuntu 12.04 LTS and came with a basic set of tools and utilities along with the requisite drivers/patches. The exception being the touchpad driver which at that point didn’t provide full support and lacked, among other things, palm rejection. This meant that if the user’s palm brushed the pad the cursor would leap across the page. We clearly stated the issue explaining that we had contacted the vendor and in parallel we were working with Canonical to deliver an interim solution.
Our ask of the community was to provide their feedback on the system, the OS and the overall project. More specifically we wanted to know what they most wanted to see in a developer laptop.
From there, interest kept growing and over the next few weeks we received global coverage from publications including The Wall Street Journal, Hacker News, Venture Beat, ZDNet, The Register, Forbes, USA Today, and Ars Technica.
Community input.
When Project Sputnik was announced, developers were asked to tell us what they wanted in a Linux laptop. Their requests were surprisingly modest.
Top 5 requests
Don’t make it more expensive than Windows
Make it work with the vanilla Ubuntu image
At least 8GB of RAM
No Windows Preinstalled
No CD/DVD
Based on the response, along with the amount of input we received from the community, we quickly sketched out a beta program. This turned out to be the tipping point. We asked that anyone interested in participating in the program submit an online form. We expected a few hundred responses, we got over 6,000.
Hello world
This overwhelming response convinced senior management that the project was viable. We were given the go ahead and four short months later the Dell XPS 13 developer edition debuted in the US and Canada.
The 1st generation Dell XPS 13 developer edition. For this initial launch the team erred on the side of caution and offered only one configuration. The config they chose was the highest available at the time: 3rd gen Intel core i7, 8GB RAM, 256GB SSD and a screen resolution of 1366×768.
At launch the product received more attention and coverage than our original announcement.There were however two complaints, the screen resolution was too low (1366×768), and the system wasn’t available outside the US and Canada. We took this input to heart and two and a half months later we introduced a Full HD (FHD) display (1920 x 1080), and the XPS 13 developer edition debuted in Europe.
Going big with Precision
Something else we started hearing from a segment of the community was, although they liked the idea of a developer system, the svelte XPS 13 developer edition wasn’t powerful enough for their needs. They were looking for a bigger screen, more RAM and storage, and beefier processors. The system they had their eye on was the Dell Precision 3800 mobile workstation. Unfortunately, at that point our little team didn’t have the resources to enable and support an additional developer system. Realizing this, team member Jared Dominguez, whose official job was on the server side of the house, took a 3800 home and got to work enabling Ubuntu on the mobile workstation. Not only did Jared get the system up and running but he carefully documented the process and posted a step-by-step installation guide on Dell’s Tech blog. People ate it up.
Jared hacking in his hammock
How to get Ubuntu up and running on your Precision workstation
Instead of satisfying their desire for a more powerful system, Jared’s post only served to increase the demand for an officially price-listed offering.
Community feedback in hand, the project Sputnik team took our learnings to the workstation group and convinced them of the opportunity. The Precision team dug in and a year later the Ubuntu-based Dell M3800 Precision mobile workstation became available (virtually doubling Dell’s developer product line). Not long after that, the developer portfolio more than doubled again when the Precision team expanded their mobile line up from one to four systems, each of which was available as a developer edition.
Today the Dell XPS 13 developer edition is in its 12th generation. On the Precision side, the mobile workstation line is in its 8th generation and has been joined by the fixed workstation line. Besides Ubuntu, both the fixed and mobile workstations are certified to run Red Hat and, in the case of the fixed systems, they are available from the factory with Red Hat preloaded. Additionally, the Precision portfolio now contains both developer-targeted systems as well as Data Science and AI-ready workstations.
And while Dell’s developer line is its most visible Linux-based offerings, these offerings make up only a fraction of the over 100 systems that comprise Dell’s broader Linux portfolio.
Not always a cake walk
Over the last 10 years, while the project has gone from a single product to a broad portfolio, the first years weren’t exactly smooth sailing. While there were always a variety of individuals and teams who were willing to help out, there were also many who saw the effort as a waste of resources. In fact, in the first few years the team found themselves more than once in the cross hairs of one department or another.
When we reached the three-year mark, it looked like Project Sputnik had finally used up its nine lives. Dell was looking to focus resources and planned to pare down across the board. Given the previous few years it was no surprise when we were told it was almost certain that the developer line would not make the cut. At that point I remember thinking, we’ve had a good run and can be proud of having made it as far as we did.
We still don’t know what happened, but once again providence shown and, for some reason, the axe never fell.
Going forward
As we head into our next decade, we find ourselves in a different environment. Ten years ago, most Dell employees saw developers as a niche market at best, today that’s changed. With the continuous rise of DevOps and platform engineering, the broader Dell has recognized the importance of developers alongside operations.
In light of this, Dell’s overall product portfolio, from laptops, to server and storage solutions is now being designed with developers in mind. To ensure that developers’ requirements are being accurately reflected, Dell has recently established a developer relations team and has brought in key figures from the community to serve as developer advocates.
In the case of the existing developer portfolio, besides looking for more opportunities to connect client systems to back-end systems, Dell is looking at various ways to broaden the portfolio on the client side. The team is currently in the early stages of brainstorming and are looking at a variety of options. Stay tuned!
At Kubecon NA 2022 I came across the Dell XPS 13 Plus developer edition being offered as the grand prize at the Canonical booth
Thank you
A few groups that need to be called out for making this possible:
A big thank you to Canonical who has worked hand in hand with us to deliver and expand our developer line and a shout out to those at Dell who, on top of their day jobs, have given their time and support. Finally, a huge thank you the developer community for making project Sputnik a reality. Over the last ten years you in the community have let us know what you’ve liked and where we could do better. It’s because of this amazing support that not only are we still here 10 years later, but it looks like we’ll be around for awhile 😊
Epilogue — 5 things we learned
Over the last 10 years the team has learned quite a bit and has the scars to prove it. Here are our top five leanings
You’re good enough… No one knows it all so build a great team and take the leap
Get a champion, be a champion – You need to have someone high up to go to bat for you at critical moments but on a day-to-day basis it’s you who must be a tireless champion
Leverage, execute – It doesn’t matter if it’s your idea or not, delivery is what counts
Start small – Don’t over promise, stay focused and err on the side of caution
Communicate, communicate, communicate – Stay in constant contact with the community, speak directly and with empathy and when you screw up or fail to deliver, own it
Post Script – Why “Sputnik”?
You may be asking yourself, why did they name it “Sputnik” in the first place? The project name is a nod to Ubuntu founder and Canonical CEO, Mark Shuttleworth who, 10 years before the project itself, spent 8 days craft orbiting the earth in a Soviet space (while the ship was actually Soyuz, it didn’t have an inspiring ring to it so we went with “Sputnik” instead.)




 Posted by Barton George
Posted by Barton George