About a month ago I wrote about my frustration with ChatGPT-4o’s pull-down menu and its mess of mismatched models. I ended my post saying that I hoped ChatGPT 5 would address this. Last Thursday my prayers were answered. The pull-down was gone and with it the hodgepodge of models. In its place there was one simple clean button.
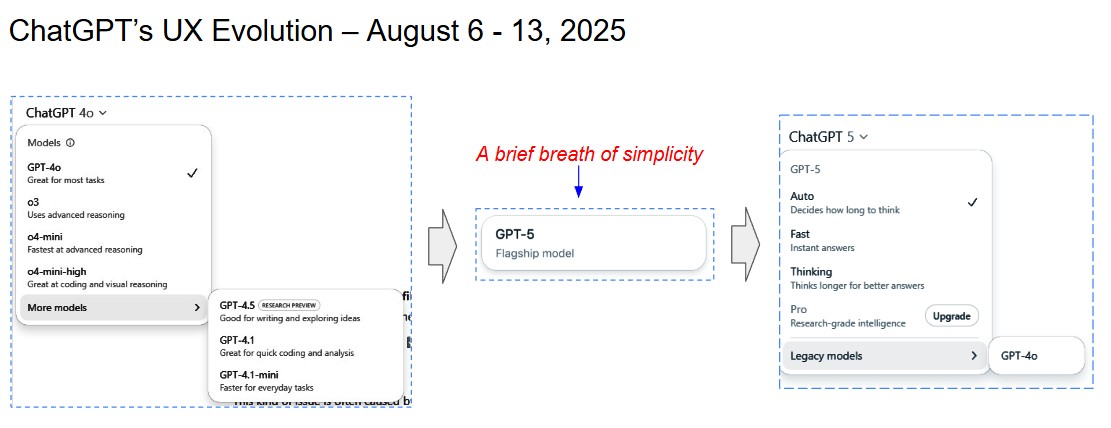
The backlash
Not long after the new model and its clean UX debuted, a hue and cry erupted in the web-o-sphere. The biggest complaint was the disappearance of GPT-4o. People were both angry and frustrated at the loss of friendliness and companionship that 4o brought (not to mention the fact that it had been incorporated into many workflows). To OpenAI’s credit they listened and responded. Within days 4o was back on the home screen as a “legacy model.”
Fun fact!

When I first started writing this, I wasn’t sure which keys to hit when typing “4o.” The “0” looked a couple of points smaller than the “4,” but I couldn’t quite tell. After asking the source, I learned it wasn’t a zero at all—it was a lowercase “o.” It turns out the “o” stood for omni, signaling multimodal capability. (I’ve got to believe that I’m not the only one surprised and confused by this)
As a follow up I asked if GPT-5 is multimodal. The answer: “Indeed.” Which then raises another question—why isn’t it called “GPT-5o”? But I digress.
The return of the pull-down
Along with 4o, came the reintroduction of the pull-down menu which, in addition to the “Legacy Models” button, presented four thinking modes to choose from (it seems the thinking modes were added in response to what some users felt was GPT-5’s slow speed and lack of flexibility).
- Auto – decides how long to think
- Fast – instant answers
- Thinking – thinks longer for better answers
- Pro – Research-grade intelligence (upgrade)
While power users must have rejoiced, I found myself, once again, confronted with a set of options lacking helpful explanations. While it was certainly an improvement over GPT-4o’s mess of models and naming conventions I found myself left with many questions:
While power users must have rejoiced, I found myself, once again, confronted with a set of options lacking helpful explanations. While it was certainly an improvement over GPT-4o’s mess of models and naming conventions I found myself left with many questions: What criteria does Auto use to determine how long to think? What tradeoffs come with Fast? What exactly qualifies as “better” in Thinking? if I’m impatient will I get lesser answers? And what the heck is “research-grade” and why would I pay more for it?
Just like GPT-4o where I rarely ventured beyond the main model, so far I have kept GPT-5 in auto mode.
Grading the model
Before grading the models myself I decided to get ChatGPT 5’s thoughts. I asked the AI to focus its grading on the UX experience, specifically to what extent a user would be able to quickly and confidently pick the right mode for a given task.

Surprisingly, it graded itself and its predecessor just as I would have. GPT-5 gave the GPT-4o UX a C– and its own, a B-. From there it went through and critiqued the experiences in detail.
At the very end, GPT-5 offered to put together a proposal for a “redesigned hybrid menu that takes GPT-5’s simplicity and pairs it with short, task-oriented descriptions so users can choose confidently without guesswork.” If only OpenAI had access to a tool like this!
Your mileage may vary
Over the past week I’ve used GPT-5 a fair amount. While I can’t measure results objectively, Auto seems to choose well. Writing, research, and analysis have been solid.
Compared to 4o I found that it spent significantly more time researching and answering questions. Not only have I noticed the increase in thinking time, but for the first time I witnessed “stepwise reasoning with visible sub-tasks.” Component topics were flashed on the screen as GPT-5 focused on each one at a time. The rigor was impressive, and the answers were detailed and informative.
Was it an improvement over 4o? Hard to tell—but the process felt more deliberate and transparent, even if it took longer.
Back to UX
And yet, we’re back to a cluttered pull-down. OpenAI isn’t alone—Anthropic and Gemini also present users with a maze of choices that lack clarity. What’s surprising is how little attention is paid to basic UX. Even simple fixes—like linking to a quick FAQ or watching a handful of users struggle through the interface—would go a long way.
As LLMs become interchangeable, the real competition will move higher up the stack. At that point, user experience will outweigh minor gains in benchmarks. It makes sense to start practicing now.
Pau for now…



 Posted by Barton George
Posted by Barton George