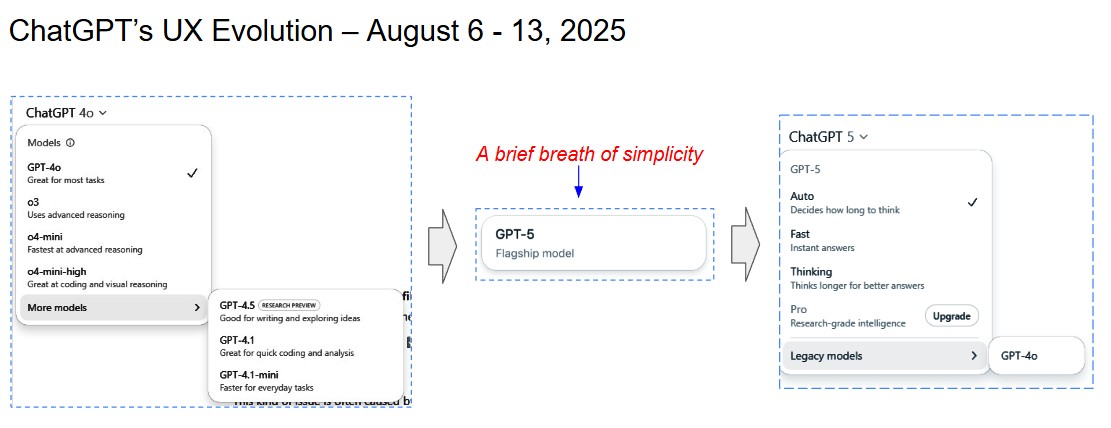
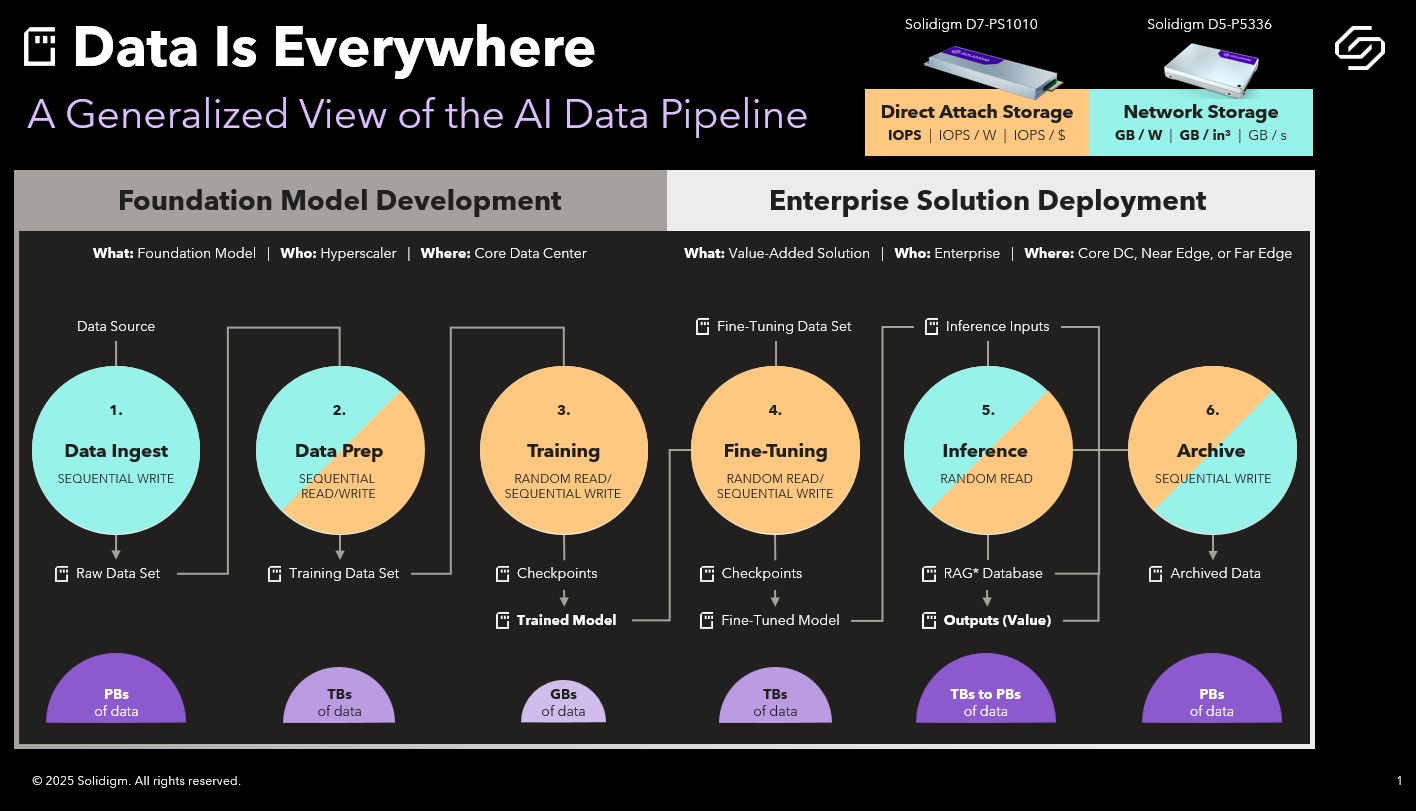
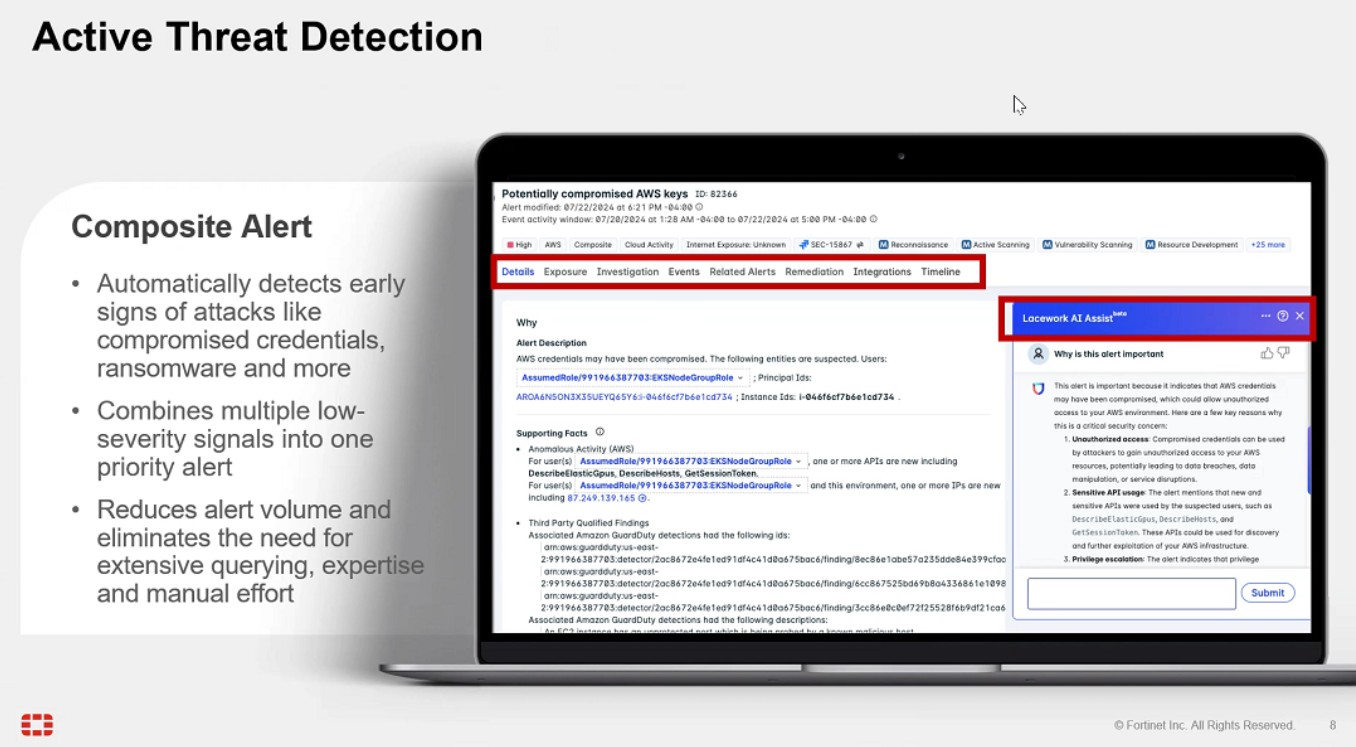
The industry is sitting on the edge of its collective seat as it awaits the release of DeepSeek V4 – which some are expecting next week. DeepSeek, you may remember, was the AI model that debuted a little over a year ago, rocking the AI world and tanking the entire market (not to mention giving NVIDIA the dubious distinction of being the company that lost more market cap in a single day than any other company in history).
What a coincidence, then, that two stories came out this past week painting DeepSeek, and the Chinese government, in a negative and nefarious light (I don’t think the accusations are spurious, but the timing is impeccable). The first story broke on Monday and involved “distillation.” The second appeared the following day, involving GPU access and the shutting out of American chip manufacturers.
Distillation disturbance
On Monday, Anthropic claimed that DeepSeek and two other Chinese AI companies used fake accounts to distill Claude. Distillation, as eWeek describes it, is “a common AI technique where one model learns from another model’s outputs, often to produce a smaller or cheaper system that behaves more like a stronger one.”
The danger, Anthropic asserted, is that models created through illicit distillation are likely to lose the safety guardrails built into American AI systems, such as protections that prevent misuse for bioweapons, cyberattacks, mass surveillance, and more. On top of that, Anthropic argued that distillation also lets Chinese labs bypass U.S. chip export controls by copying U.S. models directly, making their progress look like innovation when it might rely on stolen capabilities.
This leads us to the second DeepSeek-related story of the week, this one involving illicit GPU access and more.
NVIDIA and AMD iced out of early optimization opportunity
The following day Reuters posted an exclusive, “DeepSeek withholds latest AI model from US chipmakers including Nvidia.” DeepSeek, it seems, broke convention by not prioritizing Nvidia and AMD for early software optimization. Instead, Chinese chipmakers — including Huawei — were given a head start. Thanks to advances in AI coding tools and the ability to quickly optimize, however, this early access doesn’t provide the advantage it once did. That being said, it does send a clear message Stateside.
Clusters in Inner Mongolia
On top of this snub, the article quoted US officials as saying that, despite an export ban to China, DeepSeek had been trained on illegally obtained Blackwell chips clustered at a data center in Inner Mongolia. For reference, Blackwell is NVIDIA’s newest and most powerful GPU, whereas the chips previously allowed for export are restricted, scaled-down versions meant to comply with export controls — the NVIDIA H20 and AMD MI308 (slotting between NVIDIA’s H20 and Blackwell chips is H200, whose shipments to China have been stalled over approval guardrails).
Of course, whether China’s access to the latest GPU technology is a good or bad thing with regard to US AI competitiveness depends on who you ask. Anthropic’s CEO Dario Amodei strongly supports tighter export controls and restricting chip sales to China, whereas Nvidia’s CEO Jensen Huang argues that selling advanced chips to China can slow domestic competitors like Huawei by keeping them dependent.
The LLM that came in from the cold
This is intrigue worthy of a John le Carré spy thriller. Both stories point to growing brinkmanship between the two superpowers over AI hegemony. It is characterized by cloak-and-dagger tactics, fears of national security, and opposing views on the same side. This space keeps getting more and more interesting.
Pau for now…



 Posted by Barton George
Posted by Barton George