One of the companies that impressed me at AI Infrastructure Field Days was Solidigm. Solidigm, which was spun out of Intel’s storage and memory group, is a manufacturer of high-performance solid-state drives (SSDs) optimized for AI and data-intensive workloads. What I particularly appreciated about Solidigm’s presentation was, rather than diving directly into speeds and feeds, they started by providing us with a broader context. They spent the first part of the presentation orientating us and explaining the role storage plays and what to consider when building out an AI environment. They started by walking us through the AI data pipeline: (for the TL;DR see “My Takeaways” at the bottom)
Breaking down the AI Data Pipeline
Solidigm’s Ace Stryker kicked off their presentation by breaking the AI data pipeline into two phases: Foundation Model Development on the front end and Enterprise Solution Deployment on the back end. Each of these phases is then made up of three discrete stages.

Phase I: Foundation Model Development.
The development of foundation models is usually done by a hyper-scaler working in a huge data center. Ace defined foundation models as typically being LLMs, Recommendation Engines, Chatbots, Natural Language Processing, Classifiers and Computer Vision. Within foundation model development phase, raw data is ingested, prepped and then used to train the model. The discreet steps are:
1. Data Ingest: Raw, unstructured data is written to disk.
2. Data Preparation: Data is cleaned and vectorized to prepare it for training.
3. Training: Structured data is fed into ML algorithms to produce a base (foundation) model.
Phase II: Enterprise Solution Deployment
As the name implies, phase II takes place inside the enterprise whether that’s in the core data center, the near edge or the far edge. In phase II models are fitted and deployed with the goal of solving a specific business problem:
4. Fine-Tuning: Foundation models are customized using domain-specific data (e.g., chatbot conversations).
5. Inference: The model is deployed for real-time use, sometimes enhanced with external data (via Retrieval Augmented Generation).
6. Archive: All intermediate and final data is stored for auditing or reuse.
Data Flows and Magnitude

From there took us through the above slide which lays out how data is generated and flows through the pipeline. Every item above with disk icon represents the substantial data that is generated during the workflow. The purple half circles give a sense of the relative size of the data sets by stage. (an aside: it doesn’t surprise me that Inference is the stage that generates the most data but I wouldn’t have thought that Training would be significantly less than the rest).
Data Locality and I/O Types
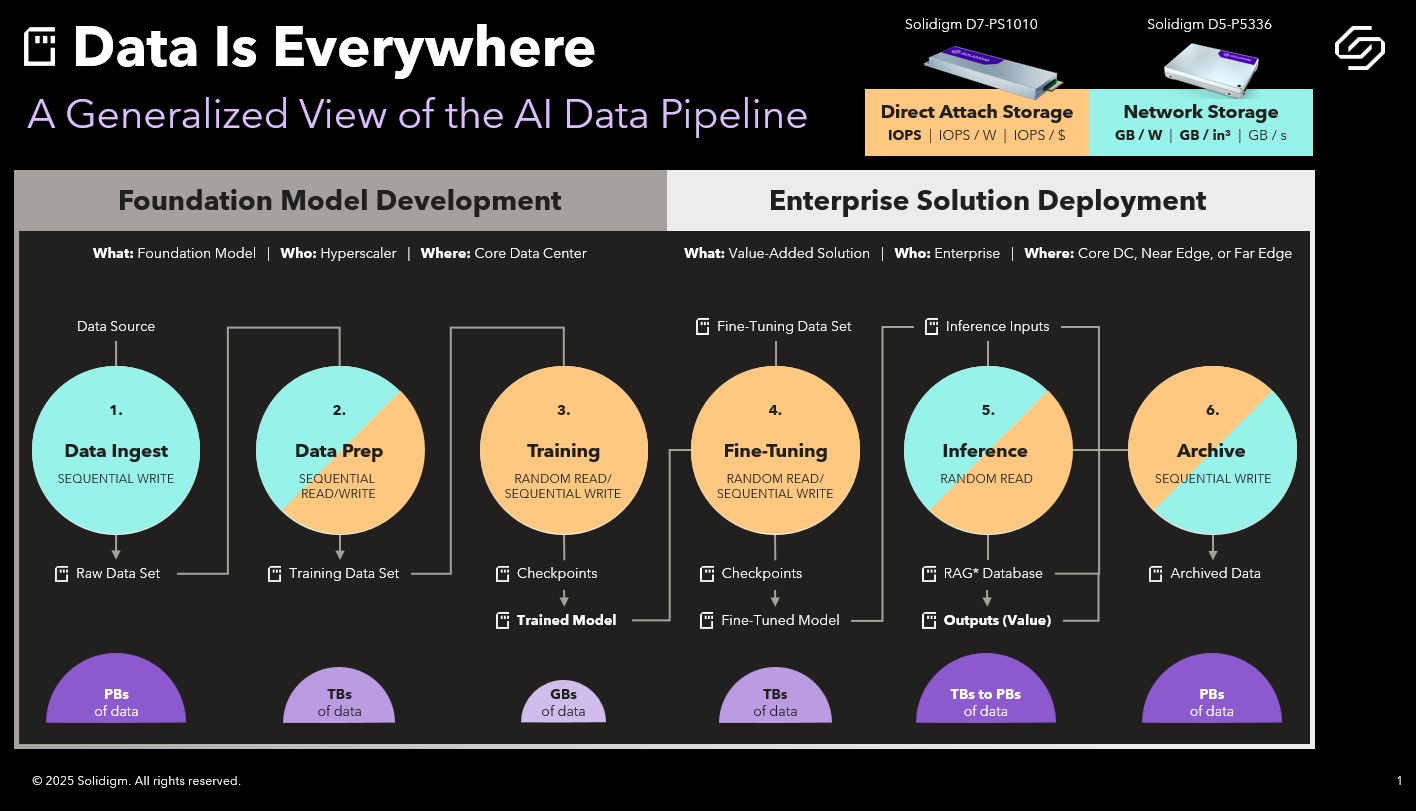
Ace ended our walk through by pointing out where all this data is stored as well as what kinds of disk activity takes place at each stage.
Data Locality:
Above, Network Attached Storage is indicated in blue and Direct Attached Storage is called out in yellow ie Ingest is pure NAS, Training and Tuning are all DAS, Prep, Inference and Archive are 50/50. Basically, early and late stages rely on network-attached storage (NAS) for capacity and power efficiency. Middle stages, on the other hand, use direct-attached storage (DAS) for speed, ensuring GPUs are continuously fed data. The takeaway: direct attached storage for high-performance workloads and network storage for larger, more complex datasets.
I/O Types:
As Ace explained, it’s useful to know what kinds of disk activity are most prevalent during each stage. And that knowing the I/O characteristics can help ensure the best decisions are being made for the storage subsystem. For example,
- Early stages favor sequential writes.
- Training workloads are random read intensive.
Something else the presentation stressed was the significance of GPU direct storage, which can reduce CPU utilization and improve overall AI system performance by allowing direct data transfer between storage and GPU memory.
My takeaways
- It may sound corny but Data is the lifeblood of the AI pipeline
- The AI data pipeline has both a front end and a back end. The back end usually sits in a hyperscaler where, after being ingested and prepped, the data is used to train the model. The front end is within the enterprise where the model is tuned for business-specific use then used for inference with the resulting data archived for audits or reuse.
- Not only is there a lot of data in the pipeline but it grows (data begets data). Some stages amass more data than others.
- There isn’t one storage type that dominates. In those stages like Data Ingest where density and power efficiency are key you want to go with NAS whereas in areas like Training and Fine Tuning, where you want performance to keep the GPUs busy, DAS is what you want.
Pau for now…

[…] Extra-credit reading:Why Storage Matters in Every Stage of the AI Pipeline […]
LikeLike